
Optimizing SQL Queries With Code Examples In Go

Table of Contents
SQL databases are ubiquitous in modern applications, powering everything from simple web apps to complex enterprise software. SQL databases are designed to store and retrieve data efficiently.
Scalability and performance are important metrics you’ll pay attention to as you build your applications. Optimising SQL queries is important to your app’s performance. Optimizing queries involves tuning queries to make them faster and more efficient, involving rewriting queries, caching, query simplification, indexing, and connection pooling, amongst other measures.
Slow queries can slow down your application’s performance and harm business outcomes. By optimizing your SQL queries, you enable your app to handle more requests and process data quickly.
In this tutorial, you’ll learn how to optimize SQL queries for your Go applications with GORM and the Postgres DBMS. You’ll learn how to use various optimization techniques, including indexing, query simplification, caching, and connection pooling.
Prerequisites
To follow up and understand the content of this article, you’ll need to meet the following requirements:
Working experience with the Go programming language as this article will use the Gorm library to interact with the database. Knowledge of SQL databases and running SQL queries. Also, make sure you have Go installed on your computer.
You can learn more about building applications with GORM from this article on building REST APIs with Gin and GORM.
Setting Up Your Development Environment
To get started, run this command in the terminal to initialize a new Go project in your working directory:
go mod init OptimizeSQLThen, install the GORM ORM and the Postgres driver as dependencies for your package with these commands:
go get -u gorm.io/gorm
go get gorm.io/driver/postgresThese packages will help you interact with the database from your Go app.
Run these commands to create a new Go project and a main.go file for the programs in this article
go mod init
touch main.go && echo package main >> main.goThe go mod init command initializes a Go project and the touch main.go && echo package main >> main.go command creates a main.go file before adding the package main declaration to the file.
Here’s how you can import the Postgres driver and GORM ORM for use in your program:
import (
"gorm.io/driver/postgres"
"gorm.io/gorm"
)You’ll need to connect to your database to execute queries. Here’s how to use the Postgres driver to connect to a Postgres database with GORM.
First, define a struct for the fields of your database connection string:
type Config struct {
Host string
Port string
Password string
User string
DBName string
SSLMode string
}Create a function that establishes a database connection using the configuration structure provided above. Inside this function, ensure the connection string is formatted correctly:
func NewConnection(config *Config) (*gorm.DB, error) {
dsn := fmt.Sprintf("host=%s port=%s user=%s password=%s dbname=%s \
sslmode=%s", config.Host, config.Port, config.User, config.Password, \
config.DBName, config.SSLMode)
db, err := gorm.Open(postgres.Open(dsn), &gorm.Config{
NamingStrategy: schema.NamingStrategy{
SingularTable: true,
},
})
if err != nil {
return db, err
}
err = db.AutoMigrate(&Human{})
if err != nil {
return nil, err
}
return db, nil
}The NewConnection function creates a new database connection by using a pointer to the Config struct as an argument. The Config struct is initialized to contain the information required to establish a database connection, such as the hostname, port number, username, password, database name, and SSL mode.
The function then constructs a (DSN (Data Source Name))[https://www.connectionstrings.com/dsn/] string using the configuration information with the fmt.Sprintf() function to format the string with the variables provided.
The gorm.Open function creates a new database connection with the Postgres database driver. If the connection is successful, the function returns the gorm.DB object (the database instance object) and a nil error. If there is an error, the function returns a nil gorm.DB object and the error.
You’ll need to populate your database with data to execute the examples in this tutorial. You can find the program and the schema struct for populating the database table on this GitHub gist.
Understanding the Query Execution Plan
Understanding the Query Execution Plan is crucial for optimizing SQL queries. The Query Execution Plan is a process that shows how database engines execute SQL queries. You can identify potential performance bottlenecks and optimize your query with a query execution plan.
The plan shows how Postgres will access and combine data from various tables and indexes and how it will filter, sort, and join the data to produce the final result for a query.
Take the following SQL Query as an example:
SELECT customer_id, COUNT(*) AS total_orders
FROM orders
GROUP BY customer_id;The SQL query retrieves the count of orders for each customer from the orders table and groups the results by the customer_id column.
When you run the query, the database engine generates a query execution plan outlining the steps for the query execution. Here’s what a query execution plan might look like on your database engine:
Aggregate (Cost: 100)
-> Sort (Cost: 50)
-> Hash Join (Cost: 20)
-> Seq Scan on orders (Cost: 10)
-> Hash (Cost: 10)
-> Seq Scan on customers (Cost: 10)Each step in the query execution plan has an associated cost representing an estimated amount of the resources required to execute the step. The cost is usually based on factors from the size of the tables involved to the number of indexes and the complexity of the operations.
Keeping the query execution plan in context can help you write better queries by understanding the execution flow of your queries.
Indexing as a Method of Optimizing SQL Queries
Indexing is a technique for improving the performance of queries by creating a data structure that allows the database to find rows matching given criteria quickly.
You’ll create indexes on frequently used columns to improve the speed of querying those columns since the database engine won’t have to scan the entire table.
Creating Indexes in PostgreSQL
You’ll use the CREATE INDEX statement to create indexes on a table in PostgreSQL.
Here’s the syntax for creating indexes for your Postgres databases
CREATE INDEX index_name ON table_name (column_name [, column_name]...);Here’s an example of an index creation statement:
CREATE INDEX userindex ON users (name, age); The SQL statement creates an index named userindex on the name and age columns of the users table.
Here’s an example query function that retrieves the username and age fields from the database based on age criteria
func FindHumanByAge(db *gorm.DB, minAge int) ([]Human, error) {
start := time.Now()
var person []Human
err := db.Raw("SELECT username, age FROM human WHERE age > ?",\
minAge).Scan(&person).Error
if err != nil {
return nil, err
}
fmt.Printf("Found %d person in %s\n", len(person), time.Since(start))
return person, nil
}
func main() {
dbConnection, err := NewConnection()
if err != nil {
log.Println(err)
}
human, err := FindHumanByAge(dbConnection, 18)
if err != nil {
log.Println(err)
}
fmt.Println(human)
}The FindHumanByAge function runs a SQL statement that retrieves the username and age fields with their age field greater than the specified integer from the database.
Here’s the result from running the function before indexing:
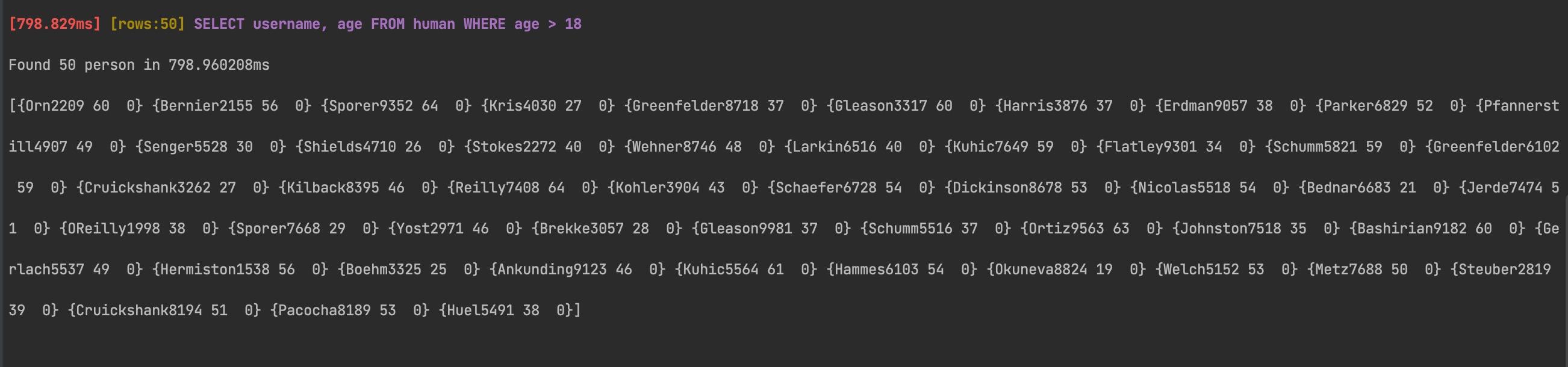
You can create indexes from your Go code with GORM as shown below:
import (
"fmt"
"time"
"gorm.io/gorm"
)
func CreateHumanIndex(db *gorm.DB) error {
start := time.Now()
err := db.Exec("CREATE INDEX human_index ON human (username, age)").Error
if err != nil {
return err
}
fmt.Printf("Created index in %s\n", time.Since(start))
return nil
}
func main() {
dbConnection, err := NewConnection()
if err != nil {
log.Println(err)
}
err = CreateHumanIndex(dbConnection)
if err != nil {
log.Println(err)
}
}The CreateHumanIndex function creates an index human_index on the human table you created and migrated data to during the database instantiation process with the GitHub gist.
After creating the index, you can now execute queries on the fields. When you execute queries on a table with indexes in PostgreSQL, the query planner will determine whether to use an index to optimize the query execution. If it uses an index, it can significantly speed up the query by providing faster access to the data.
Here’s the result of running the query after creating the `human_index index:

Notice that the query takes less time to run since there’s an index on the table. As the data size increases, you’ll save significant time while running your database operations.
Best Indexing Practices for Query Optimization
Creating appropriate indexes is crucial for optimal performance. Here are some tips you can use to improve your indexing game:
- Analyze your queries’ query patterns and access paths, and understand the query execution and data access patterns to help you understand which columns you need to index and whichindex types are most suitable.
- Choose the right columns to index. Create indexes on frequently used columns, especially where you use WHERE clauses, JOIN conditions, and ORDER BY or GROUP BY clauses since these columns are commonly used for sorting data. By indexing these columns, you can reduce the number of rows that need scanning, resulting in faster query execution.
- Avoid over-indexing, as having too many indexes can negatively impact performance since indexes require additional storage space and maintenance overhead. Consider the trade-off between the benefits and costs of maintaining indexes.
- Regularly monitor and fine-tune indexes to ensure they’re still effective. Data volumes and query patterns are dynamic, and certain indexes may be more helpful or obsolete. If you notice any performance degradation, consider re-evaluating your indexes to make necessary adjustments.
You mustn’t overcomplicate the indexing process for better results.
Query Simplification as a Method of Optimizing SQL Queries
Query Simplification is crucial in optimizing SQL queries for improved database performance. Simplifying queries helps reduce the time taken to execute queries, reduce errors, and enhance readability.
Query simplification optimizes SQL queries by transforming complex or convoluted queries into more straightforward and efficient forms. The goal of query simplification is to improve query performance by reducing query execution time, minimizing resource usage, and enhancing the overall readability and maintainability of the query.
Techniques for Simplifying SQL Queries
Generally, there are many techniques for simplifying SQL queries, including removing unnecessary subqueries, reducing the use of joins, and eliminating redundant calculations.
Here’s a SQL query that’s relatively complex and can use simplification to improve performance:
func complex(db *gorm.DB) ([]Human, error) {
var humans []Human
query := `SELECT username, age, email FROM human WHERE height > \
0.15 AND (username IS NOT NULL OR age IS NOT NULL OR email IS NOT NULL) \
ORDER BY username DESC, age ASC LIMIT 100;`
result := db.Raw(query).Scan(&humans)
if result.Error != nil {
return nil, result.Error
}
return humans, nil
}
func main() {
dbConnection, err := NewConnection()
if err != nil {
log.Println(err)
}
complexQueryExec, err := complex(dbConnection)
fmt.Println(complexQueryExec)
}The complex function runs a SQL query that selects the username, age, and email of humans taller than 0.15 meters and have a non-null username, age, or email, ordered by username descending and age ascending, limited to 100 rows.
Here’s the output and time it takes to run the query:
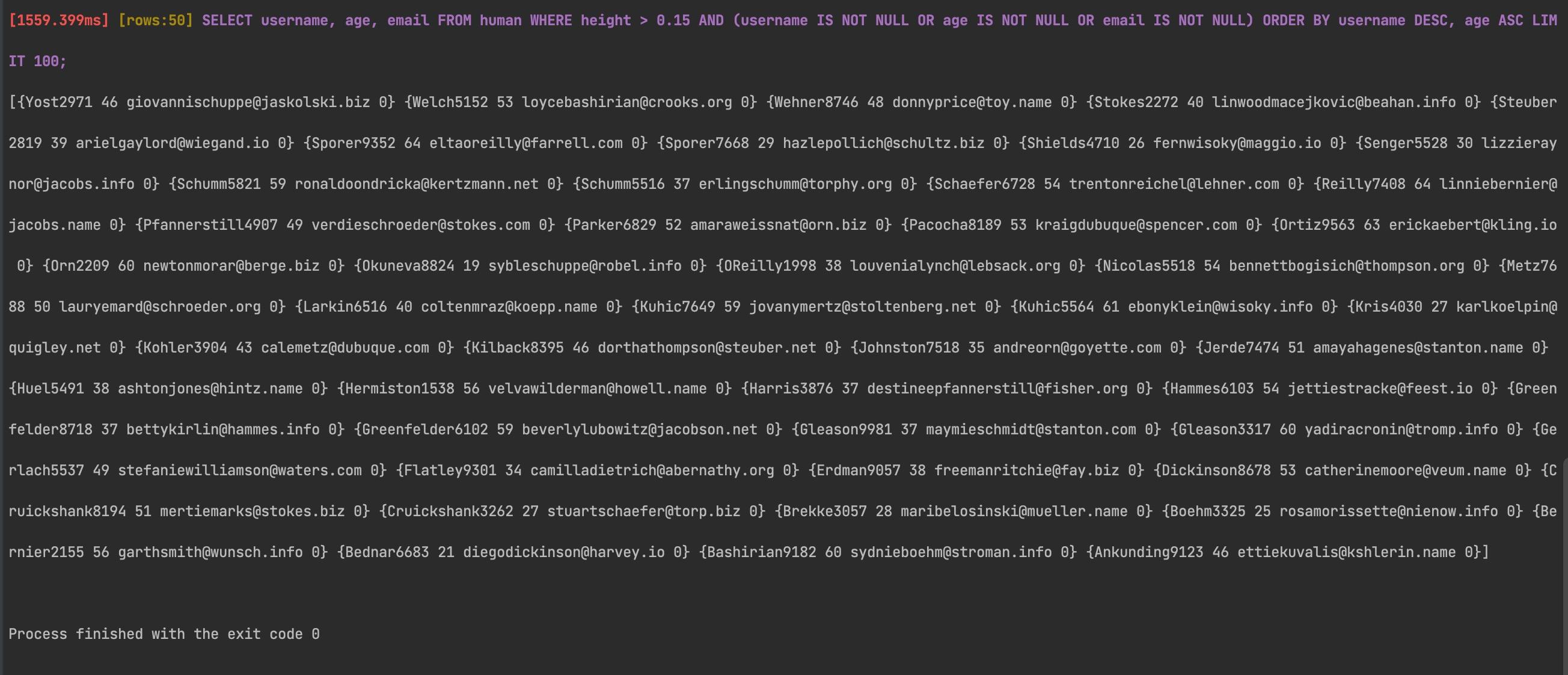
Here’s a simplified, shorter version of the query with the same functionality:
func simplified(db *gorm.DB) ([]Human, error) {
var humans []Human
query := `SELECT username, age, email FROM human WHERE height > 0.15`
result := db.Raw(query).Scan(&humans)
if result.Error != nil {
return nil, result.Error
}
return humans, nil
}
func main() {
dbConnection, err := NewConnection()
if err != nil {
log.Println(err)
}
simplifiedQueryExec, err := simplified(dbConnection)
fmt.Println(simplifiedQueryExec)
}The simplified function runs a SQL query that queries for the username, age, and email fields where the height entry is greater than 0.15 from the human table.
Here’s the output and time it takes to run the query:

Notice how the more straightforward query takes less time to execute. Query simplification is very handy, especially when you have larger datasets.
Best Practices for Query Simplification
To ensure that your SQL queries are well-optimized, employ clear and simple SQL statements while optimizing queries to enhance readability, maintainability, and debugging. Additionally, simplify complex queries to improve overall code efficiency and understandability.
Caching as a Method of Optimizing SQL Queries
Caching, as a method of optimizing SQL queries, involves storing query results or frequently accessed data in the cache to improve performance and reduce the need for repetitive query execution. Caching is a common technique for minimizing the load on a database server and decreasing response times for frequently requested data.
Techniques for Caching Query Results
There are several techniques for caching query results. One approach is to use a caching library like Sqlcache or gorm-cache that handles caching for you.
If you’re working with a database that your caching tool doesn’t support or you want full control over the caching process, you can use a technique called “Query Caching” that manually caches the results of a query in memory and then retrieves the cached results when the same query is executed again.
Best Practices for Caching
You must follow best caching practices to avoid cache expiration and stale data.
Here are three best practices for caching SQL query results:
- Cache only what’s necessary and frequently accessed. Caching unnecessary data can lead to memory bloat, which can degrade performance; therefore, it’s important to identify data needs and implement caching for those specific queries.
- Choosing the right cache expiration policy would be best to ensure that cached data isn’t stale. The cache expiration policy determines how long cached data should be stored in memory before invalidation. Set Your cache data expiration policy based on the frequency of data changes.
- Use a caching framework to simplify the process and ensure you easily follow best practices. Frameworks like GORM provide cache expiration policies and automate cache invalidation, making caching easier and more effective.
By following these practices, you’ll ensure that your programs run smoothly and efficiently.
Connection Pooling as a Method of Optimizing SQL Queries
Connection pooling is a technique for managing and sharing multiple client database connections. Connection pooling involves creating a pool of idle connections to the database that other clients can reuse instead of creating new connections per request.
Connection pooling helps reduce the overhead of creating new connections, which can be time-consuming and resource-intensive, helping your application achieve better performance, scalability, and reliability, especially under heavy traffic.
Most database packages, including GORM, provide functionality for connection pooling.
Here’s how you can implement connection pooling for your Go app:
package main
import (
"gorm.io/driver/postgres"
"gorm.io/gorm"
)
func NewPooledConnection(config *Config) (*gorm.DB, error) {
db, err := gorm.Open(postgres.New(postgres.Config{
PreferSimpleProtocol: true,
}), &gorm.Config{
NamingStrategy: schema.NamingStrategy{
SingularTable: true,
},
})
if err != nil {
return nil, err
}
// Enable connection pooling
sqlDB, err := db.DB()
if err != nil {
return nil, err
}
sqlDB.SetMaxIdleConns(10)
sqlDB.SetMaxOpenConns(100)
return db, nil
}
The NewPooledConnection function returns the GORM database instance. In the ConnectDB function, you accessed the generic database interface *sql.DB with the DB method and set the maximum idle connections to 10 with the SetMaxIdleConns method and the maximum open connections to 100 with the SetMaxOpenConns method.
Here’s the result from running the FindHumanByAge function after setting up connection pooling.
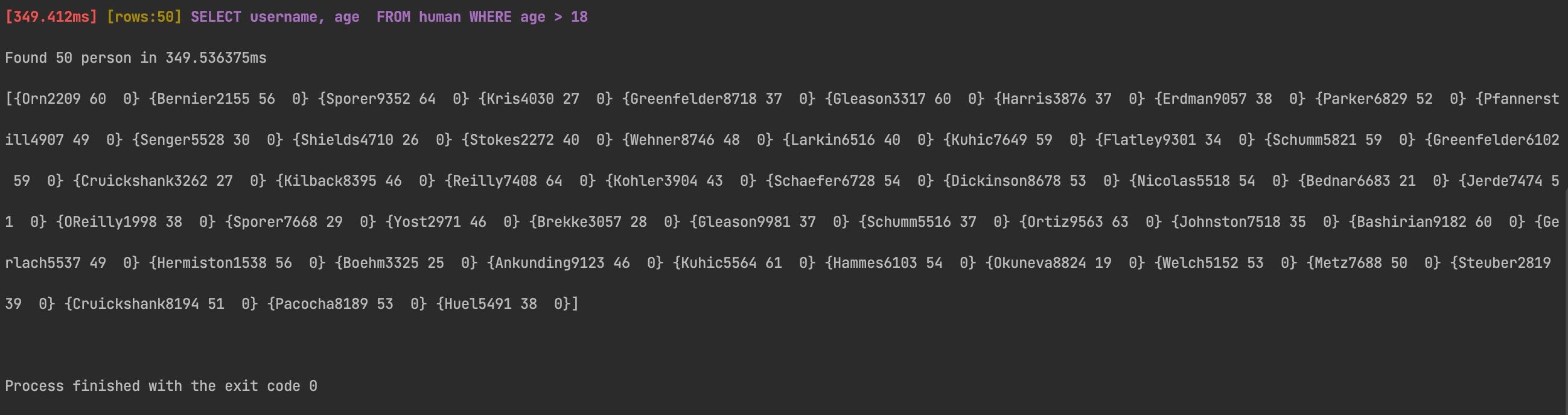
FindHumanByAge function after setting up connection poolingNotice that the FindHumanByAge query execution time has reduced significantly.
Now that you’ve implemented connection pooling, your app can achieve better performance, scalability, and reliability by reusing existing connections instead of creating new ones for each request.
Best Practices for Connection Pooling
While connection pooling is effective for optimizing SQL queries, there are some practices you need to follow for optimal performance and reliability.
Use connection timeouts to prevent idle connections from consuming resources. If connections aren’t used for prolonged periods, they can lead to resource exhaustion.
Monitor connection pool usage and performance metrics to identify potential issues and bottlenecks. You must monitor the number of connections, connection wait times, connection errors, and query execution times. You can use GORM’s built-in logger to log database operations and metrics.
Connection pooling is a convenient method of SQL query optimization when done right, especially if you need to scale your app.
Conclusion
This comprehensive exploration has equipped you with diverse strategies to optimize your SQL queries’ performance, scalability, and dependability. You’ve learned important techniques such as efficient caching, judicious query simplification, strategic indexing, and implementing connection pooling mechanisms.
If you’re searching for tools you can use to optimize your SQL queries in your Go programs, GORM is an excellent tool for working with SQL databases. You can also check out Go’s built-in database/sql tool if you prefer working with built-in tools.
Turn your engineering standards into automated guardrails that provide feedback directly in pull requests, with 100+ guardrails included out of the box and support for the tools and CI/CD systems you already have.


