
Building Real-Time Data Streaming Applications with Kafka and Asyncio

Table of Contents
Asynchronous programming allows multiple operations to run concurrently, significantly improving the efficiency of data processing applications. Apache Kafka, a distributed streaming platform, enables real-time data streaming, processing, and storage, facilitating large-scale, real-time data analytics.
A Practical Tutorial in Python
Asyncio is a Python library for writing single-threaded concurrent code using coroutines, multiplexing I/O access over sockets and other resources, running network clients and servers, and other related primitives.
In this tutorial, you will build a data streaming project using Kafka and Asyncio, leveraging the Reddit API to fetch real-time job submissions. You will cover setting up a Kafka cluster, configuring the Reddit API, creating a Kafka producer, processing the data asynchronously, and sending the data to a Kafka topic for downstream processing by a consumer.

Prerequisites
To understand this article on Kafka and asyncio, it is recommended to have a basic understanding of programming concepts such as variables, loops, conditionals, and functions. In addition, familiarity with Python syntax and basic programming constructs is necessary. Lastly, a basic understanding of networking is also required, especially in client-server communication.
Before you start, you need to have the following installed on your system:
You will also need Apache Kafka, however, if you don’t have it installed, there will be a section in this tutorial that will show you how to install it.
Apache Kafka is written in Java, so you’ll need the Java Runtime Environment (JRE) installed on your computer. Check if Java is installed by opening a terminal and typing:
Java -versionIf Java is installed, you’ll see information about the installed version. If it’s not, you need to install it. The process varies depending on your operating system. This tutorial uses JDK version 18.0.2.
You also need to install some Python libraries.
Create a requirements.txt file that lists all the libraries you need for the project and add the following to the file:
# Libraries required for the Python project
asyncio==3.4.3
# Asynchronous I/O library for concurrent code execution.
certifi==2022.12.7
# Provides a collection of root certificates for secure SSL/TLS connections.
charset-normalizer==3.1.0
# Charset detection and normalisation library for working with character
# encodings.
fake-useragent==1.1.3
# Generates fake User-Agent strings for web scraping or automation tasks.
idna==3.4
# Library to support the Internationalized Domain Names in Applications
# (IDNA) protocol.
kafka-python==2.0.2
# Python client for Apache Kafka, a distributed streaming platform.
praw==7.7.0
# Python Reddit API Wrapper for interacting with the Reddit API.
prawcore==2.3.0
# Low-level library for accessing the Reddit API used by praw.
requests==2.28.2
# HTTP library for making requests to web servers.
update-checker==0.18.0
# Library for checking whether a package is up-to-date.
urllib3==1.26.15
# HTTP client library for making HTTP requests with various features.
websocket-client==1.5.1
# WebSocket client implementation for Python to enable WebSocket
# communication.
python-dotenv=1.0.0
# A module for managing environment variables and configuration options
# in Python applicationsIt’s recommended you create a virtual environment before installing the Python libraries. Virtual environments help avoid conflicts with the libraries you might have installed in your system.
To proceed with the tutorial, create a virtual environment, activate it, and install the requirements.
In the next section, you will install and set up the Kafka cluster that you need for this tutorial.
Setting Up the Kafka Cluster
A Kafka cluster is a set of Kafka servers that can store streams of records in categories called topics. Each record consists of a key, a value, and a timestamp. In our case, you will create a single topic called jobs, which will be used to stream data from the Reddit API.
To set up the cluster, use the following steps:
Download Apache Kafka: Visit the Apache Kafka downloads page and download the latest binary that matches your system.
Extract the Archive: Extract the file’s contents once the download is complete. You can extract the content On a Unix-based system like Linux or MacOS in the terminal as shown below:
tar -xzf kafka_2.13-3.5.1.tgzThis command will create the directory kafka_2.13-3.5.1 with the Kafka files.
Start the Kafka Services:
Apache Kafka uses ZooKeeper to store configurations for topics and permissions. Zookeeper is a service that maintains configuration, provides distributed synchronization, and is shipped together with Kafka. You need to start ZooKeeper before you start Kafka. Navigate into the Kafka directory and start the ZooKeeper service:
cd kafka_2.13-3.5.1
bin/zookeeper-server-start.sh config/zookeeper.propertiesZooKeeper will start running in the foreground and log messages to the console.
On a new terminal window/tab, navigate into the Kafka directory again and start the Kafka server:
cd kafka_2.13-3.5.1
bin/kafka-server-start.sh config/server.propertiesThe Kafka server will start in the foreground and log messages to the console.
Kafka is now successfully running on your computer.
Configuring the Reddit API
To interact with Reddit’s API, you will need a client_id and client_secret, which you can get by creating an application in Reddit’s settings. Here’s how to do that:
Sign in to your Reddit account or create a new one if you haven’t already.
Navigate to the Reddit App Preferences page.
Scroll down to the Developed Applications section and click on the Create App or Create Another App button:
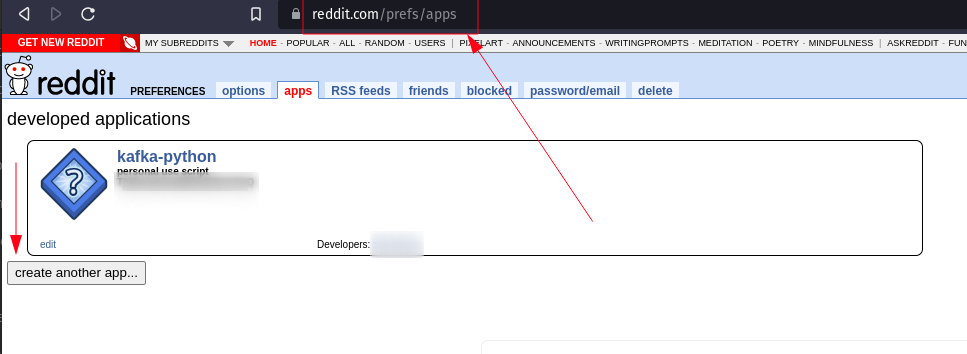
Fill out the form with the following details:
Name: Give your application a name.
App type: Choose “script”
Description: You can leave this field blank.
About URL: You can leave this field blank.
Redirect URI: This should be http://localhost:8000 (change localhost port if you prefer).
Click on the “Create app” button at the bottom of the form.
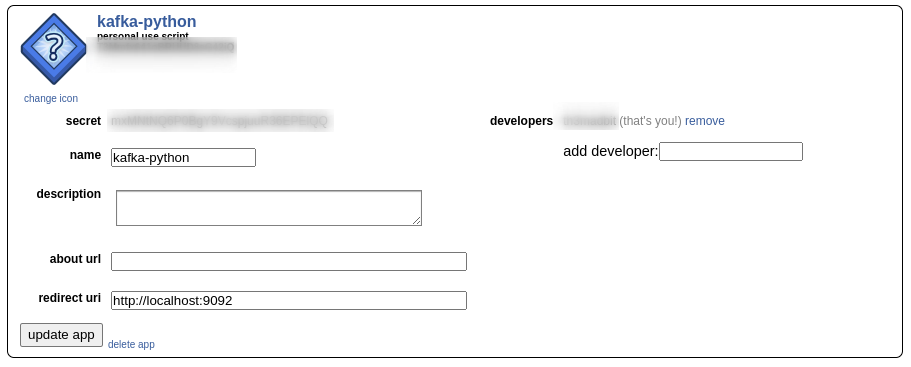
After you’ve created the app, Reddit will provide you with a client_id and a client_secret. The client_id is under the web app icon, and the client_secret is labeled secret
The upcoming sections will showcase Python code where the user_agent is randomly generated using the fake_useragent library. A “User Agent” (often abbreviated as UA) is a string that web browsers and other web clients send to web servers to identify themselves. In a production application, it’s recommended to use a static, identifiable user agent string that follows Reddit’s API rules.
With these three pieces of information, you’ll authenticate with the Reddit API and make requests. Keep your client_id and client_secret secure and never share them. They provide access to your Reddit application and should be treated like a password.
Creating the Kafka Producer
The first part of your application is the data producer. This part of the application fetches data from Reddit and sends it to Kafka.
Create a producer.py file using your chosen text editor. The file will contain all the code you need to build the data producer.
We’ll start by importing the necessary libraries.
import praw
from fake_useragent import UserAgent
import asyncio
from kafka import KafkaProducer
from dotenv import load_dotenv
import osHere is what each of the imports does:
prawis the Python Reddit API Wrapper, allowing us to interact with the API.fake_useragentis used to generate random user-agent strings.asynciois a library for writing single-threaded concurrent code using coroutines, multiplexing I/O access over sockets and other resources.KafkaProduceris a class from thekafka-pythonlibrary that allows you to publish messages to Kafka topics.dotdevis a module for managing environment variables and configuration options in Python applications.
As a security practice, you’ll use the dotenv library to read environment variables from a .env file and then pass those variables to your code.
Create a file named .env in the same directory as your Python scripts. In the .env file, store your Reddit API credentials like this:
CLIENT_ID="YOUR_CLIENT_ID"
CLIENT_SECRET="YOUR_CLIENT_SECRET"Replace "YOUR_CLIENT_ID" and "YOUR_CLIENT_SECRET" with your actual Reddit API credentials.
Add the following code to the producer.py file:
# Generate a random userAgent
ua = UserAgent()
userAgent = ua.random
# Load environment variables from .env file
load_dotenv()Next, fetch the 10 “hot” job postings from Reddit:
data = []
for submission in reddit.subreddit("jobs").hot(limit=10):
data.append({
"author": submission.author.name,
"title": submission.title,
"text": submission.selftext,
"url": submission.url
})Here, you are creating a list of dictionaries where each dictionary represents a job posting. The keys in the dictionary are the details of the job posting you are interested in.
Next, create a Kafka producer:
producer =KafkaProducer(bootstrap_servers=['localhost:9092'])The bootstrap_servers=['localhost:9092'] argument specifies the host and port where the Kafka broker runs. Change this if you are running Kafka on a different host or port.
Next, define two functions, process_data and main, to process the data asynchronously:
async def process_data(data):
await asyncio.sleep(1)
return data
async def main():
coroutines = [process_data(d) for d in data]
processed_data = await asyncio.gather(*coroutines)
return processed_dataThe process_data function simulates data processing by sleeping for one second.
The main function creates a coroutine for each job posting and waits for them to finish.
The asyncio.gather is provided by the asyncio library, takes multiple coroutine objects as arguments, and runs them in parallel (concurrently, to be more precise). When all of them are completed, the gather method returns a list of their results.
*coroutines uses the “splat” or “unpacking” operator (*) to pass the items of the coroutines list as individual arguments to asyncio.gather.
The await syntax is used to pause the execution of the main function until all the coroutines passed to gather have been completed. Once they’re done, their results are collected into the processed_data list.
Finally, send the processed data to a Kafka topic named ‘jobs’ that will be created in the consumer code:
main_data = asyncio.run(main())
for x in main_data:
print("x is ",x)
producer.send('jobs', bytes(str(x), 'utf-8'))
producer.close()In the code above, you run the main function to process all the job postings. Then, for each processed job posting, you print it and send it to the jobs topic. We convert the job posting to a string and encode it to bytes because Kafka messages must be bytes.
That’s it for the producer! It fetches job postings from Reddit, processes them, and sends them to Kafka. If you have followed the steps above, the producer should be running successfully.
The screenshot below shows that the producer fetched data from the Reddit API and printed them to the std output.
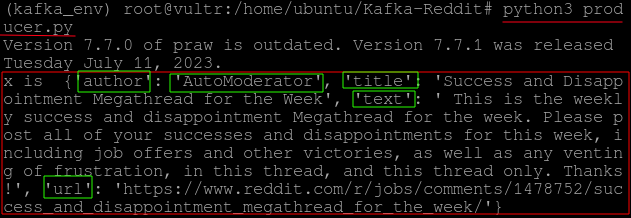
Building the Kafka Consumer
The second part of your application is the data consumer. This part listens for new messages in the Kafka topic and sends an email notification for each message.
Create a consumer.py file that will contain the consumer code.
Start by importing the necessary libraries:
import asyncio
from kafka import KafkaConsumer
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMETextKafkaConsumer is a class from the kafka-python library that allows us to consume messages from Kafka topics. smtplib and MIMEMultipart and MIMEText are classes for creating and sending emails.
We then create a Kafka consumer and specify the Kafka topic we want to consume from:
consumer = KafkaConsumer(
'jobs',
bootstrap_servers=['localhost:9092'],
group_id='OYdlvsrvTzaaCbLVniVC1Q'
)The bootstrap_servers=['localhost:9092'] parameter specifies the host and port where the Kafka broker runs on. Change this if your Kafka broker runs on a different host or port.
The group_id='OYdlvsrvTzaaCbLVniVC1Q' parameter specifies the one consumer group this consumer belongs to. Group IDs used when creating a Kafka consumer can be arbitrary, but they serve an essential purpose in Kafka’s consumer model.
Kafka delivers each message in the topics to one consumer in each consumer group. If all the consumer instances have the same consumer group, this works like a traditional queue balancing load over the consumers.
Next, we set up the email configuration:
sender_email = "YOUR_EMAIL@gmail.com"
sender_password = "YOUR_PASSWORD"
receiver_email = "THEIR_EMAIL@gmail.com"Replace “YOUR_EMAIL@gmail.com” and “YOUR_PASSWORD” with your Gmail email and password. If you use a different email provider, you should change the SMTP server and port in the send_email function.
We then define a function send_email to send an email notification:
def send_email(subject, body):
message = MIMEMultipart()
message["From"] = sender_email
message["To"] = receiver_email
message["Subject"] = subject
message.attach(MIMEText(body, "plain"))
with smtplib.SMTP("smtp.gmail.com", 587) as server:
server.starttls()
server.login(sender_email, sender_password)
server.send_message(message)This function creates a new email with the given subject and body and sends it to the receiver’s email.
Finally, we consume and process messages from Kafka:
async def consume_data():
print("consumer data called",consumer)
for message in consumer:
data_item = message.value.decode('utf-8')
subject = "Processed Data"
send_email(subject, data_item)
loop = asyncio.get_event_loop()
loop.run_until_complete(consume_data())For each message in the Kafka topic, we decode it from bytes to strings and send an email notification with the message as the body.
While authenticating with the smptlib library, you might get the following error, even when the credentials are valid:
smtplib.SMTPAuthenticationError: (535, b'5.7.8 Username and \
Password not accepted. Learn more at\n5.7.8
https://support.google.com/mail/?p=BadCredentials
k19-20020a1709061c1300b00982d0563b11sm7790611ejg.197 - gsmtpThis error typically occurs when you’re trying to send an email using Gmail and the “Less secure app access” setting is turned OFF in your Google Account settings. Google considers SMTP clients like the one used in your Python script less secure than Google apps and apps that support OAuth 2.0, so it prevents them from logging in by default.
For a higher security standard, Google now requires you to use an “App Password”. An app password is a 16-digit passcode generated in your Google account and allows less secure apps or devices that don’t support 2-step verification to sign in to your Gmail Account.
Here’s a guide from Google support on how to generate app passwords. That’s it for the consumer! It listens for new messages in the Kafka topic and sends an email notification for each message asynchronously.
Run the two files to stream your data from the producer to the consumer. Preferably, run them in two terminal instances for better and cleaner results:
 Producer and consumer applications are running!
Producer and consumer applications are running!
 The email with your subject should be sent!
The email with your subject should be sent!
Conclusion
This tutorial introduces you to the power of real-time data streaming applications using Kafka and Asyncio. You’ve walked through a practical example that fetches real-time job submissions from the Reddit API, processes them asynchronously, and streams them to a Kafka topic for downstream processing. This application is just the tip of the iceberg for what can be achieved with Kafka and Asyncio. In a business context, these technologies can be used for marketing and sentiment analysis, trend analysis and predictions, social media analytics, and much more. As you gain more experience with these technologies, you’ll find they are powerful tools for handling Big Data and performing real-time analytics. The final code can be found in this repository.
Turn your engineering standards into automated guardrails that provide feedback directly in pull requests, with 100+ guardrails included out of the box and support for the tools and CI/CD systems you already have.


