
Getting Started with Terraform `depends_on` to Specify Dependencies

Table of Contents
Infrastructure as code (IaC) refers to the methodology of managing and provisioning infrastructure, servers, load-balancers and other hardware, using code. Essentially, it involves defining and handling all the components of your infrastructure, such as servers, networks, databases, and load balancers, through code.
Terraform is a popular open-source IaC tool that provides a domain-specific language (DSL) (ie HashiCorp Configuration Language (HCL)) for defining infrastructure configurations. It uses a declarative syntax to define the desired state of the infrastructure rather than prescribing a series of steps to achieve that state. This means that instead of writing detailed procedural instructions, you can specify the final desired state, and Terraform figures out the necessary actions to reach that state.
In Terraform, configuration files define the desired state of the infrastructure and hold all the resource dependencies. Resource dependencies are responsible for specifying relationships between different resources. This arrangement ensures that certain resources are created or modified before others.
To explicitly define these dependencies, Terraform provides the depends_on attribute. With it, you can explicitly define dependencies between resources. This ensures that one resource is created or modified only after another resource has been created or modified.
In this guide, you’ll learn all about Terraform resource dependencies and how they play a crucial role in defining the order in which resources are created or modified.
Key Components of Terraform Configuration Files
Terraform configuration files define your infrastructure and are written in HCL. They typically have a .tf file extension where you define resources, their properties, and any dependencies between them. If you want to make the configurations more flexible and reusable, you can also use variables, modules, and data sources.
There are four key components of a Terraform configuration file:
Providers are plugins that interface with your specific cloud provider or infrastructure platform. You declare the provider and its configuration details, such as access credentials and region.
For instance, if you’re using Amazon Web Services (AWS) Cloud and want to create resources in the
eu-west-1region, you would specify the provider like this:provider "aws" { region = "ca-central-1" # Replace with your desired AWS region }Resources help you declare the infrastructure components that you want to create and manage. Each resource has its type and set of properties.
For example, take a look at this Amazon Simple Storage Service (Amazon S3) bucket resource:
resource "aws_s3_bucket" "my_bucket" { bucket = "my-bucket" }Here, the
aws_s3_bucketresource represents an Amazon S3 bucket in the AWS provider. The resource block defines a specific instance of the S3 bucket with the namemy_bucket.Variables let you parameterize your configurations, making them more flexible. You can define variables with default values or prompt the user for input during runtime.
Outputs define the values that are useful to display or pass to other Terraform configurations. For instance, you can output the IP address of a provisioned virtual machine.
State and Modules Concepts in Terraform
Other related Terraform IaC concepts include state and modules. Terraform uses a state file to track the current state of your infrastructure. This file determines which resources need to be created, updated, or deleted when you run a Terraform plan or apply command.
modules are a way to organize your Terraform configuration files and can be reused across multiple projects. This helps to keep your code DRY (Don’t Repeat Yourself).
If you want to follow along with some of the examples used here, you’ll need the following:
- Terraform version 1.5.4 (or later) installed. This is the latest version at the time of writing and provides the most recent improvements and features.
- An AWS Account and the latest version of the AWS Command Line Interface (AWS CLI) installed.
Even though the examples are using AWS, it’s important to note that Terraform also supports a wide range of other cloud providers, including Azure and Google Cloud.
Additionally, you need to configure Terraform to work with your AWS Account.
You also need to create a directory named terraform_dependencies, where you’ll eventually store the Terraform code that demonstrates dependencies.
All the code used here can be found in the main_explicit.tf file of this GitHub repo.
Understanding Resource Dependencies
Terraform resources can have dependencies on other resources. This means that Terraform does not create or update a resource until all its dependencies have been created or updated.
Terraform automatically analyzes the dependencies between resources based on their configurations and ensures that resources are provisioned in the correct sequence. This helps to maintain consistency and avoids issues where resources are referenced before they’re available.
There are two types of dependencies in Terraform: explicit and implicit dependencies. Take a look at each:
Explicit Dependencies in Terraform
Explicit dependencies are dependencies that must be explicitly declared in the configuration of the resources. This is done using the depends_on argument, which allows you to specify a list of dependencies for a particular resource. By adding this argument to a resource block, you inform Terraform about the explicit dependency relationship. When Terraform executes its provisioning or modification actions, it respects these dependencies and ensures the specified resources are created or modified in the desired order.
The depends_on argument is added within a resource block, and it takes a list of resource dependencies. The depends_on syntax looks like this:
resource "resource_type" "resource_name" {
...
depends_on = [resource_type.resource_name, ...]
...
}To better understand how explicit dependencies using depends_on work, create a main.tf file in your terraform_dependencies directory. In that file, add the following Terraform code:
provider "aws" {
region = "ca-central-1" # Replace with your desired AWS region
}
resource "aws_instance" "web_server" {
…
depends_on = [
aws_subnet.public_subnet]
}
resource "aws_subnet" "public_subnet" {
…
depends_on = [
aws_vpc.main_vpc
]
}
resource "aws_security_group" "web_sg" {
…
depends_on = [
aws_instance.web_server,
aws_subnet.public_subnet,
]
}
resource "aws_vpc" "main_vpc" {
cidr_block = "10.0.0.0/16"
tags = {
Name = "main-vpc"
}
}Here, an Amazon Elastic Compute Cloud (Amazon EC2) instance named web-server depends on an AWS public_subnet, and the public_subnet depends on the Virtual Private Cloud (VPC) (vpc_main). The EC2 instance needs the subnet to be available before it can be launched.
Additionally, an AWS security group called web-sg depends on both the EC2 instance and the subnet being available before it can be launched. The depends_on attribute ensures that the security group is created or modified only after the EC2 instance and the subnet are provisioned.
Please note: All the code used here can be found in the
main_explicit.tffile of this GitHub repo. In this example, you’re using the Canada central region to deploy resources (as specified in theproviderblock in the code), but you can change this to a different region if you prefer.
Currently, there are no instances deployed in the region and only one security group (the default):
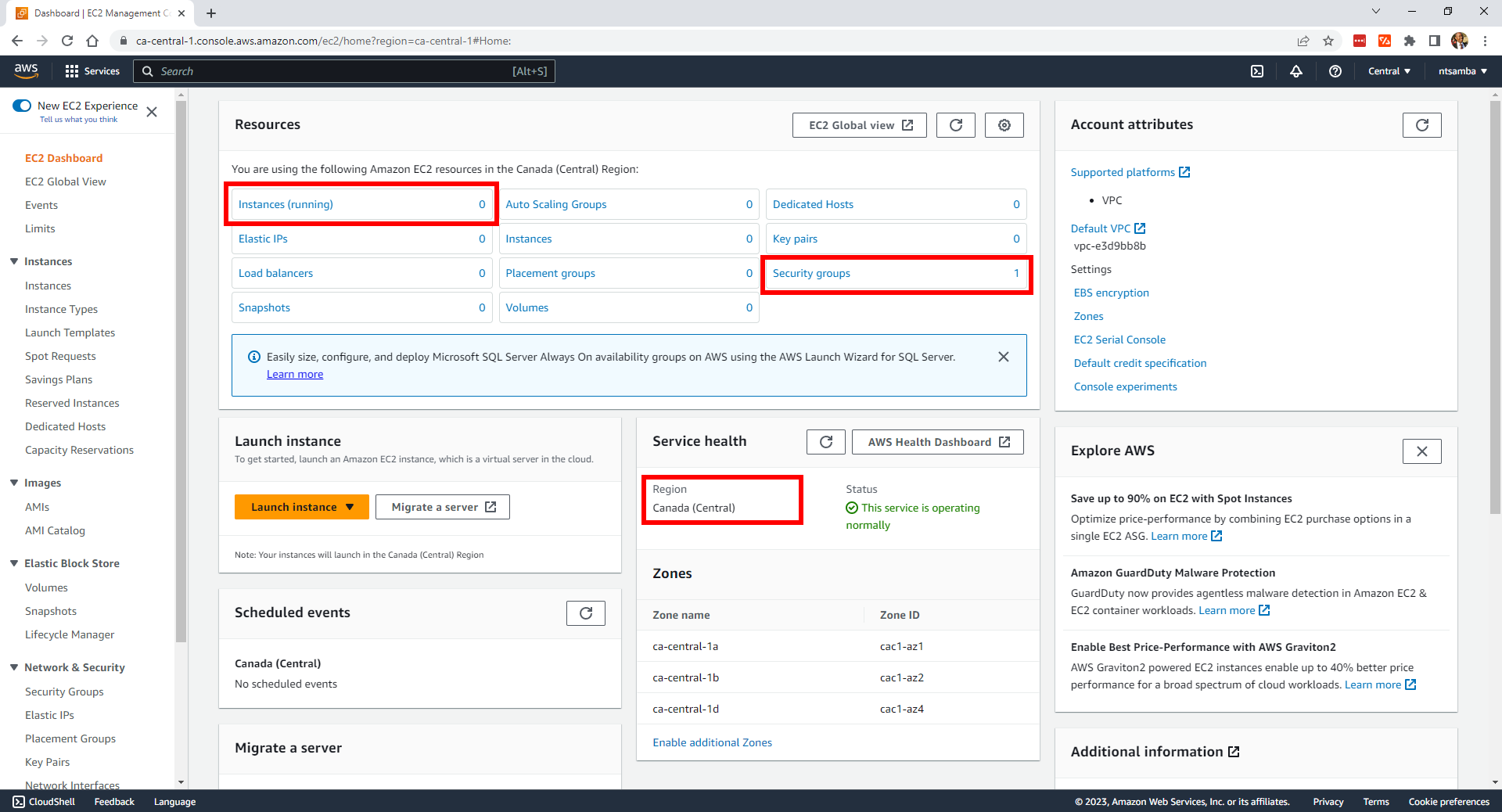
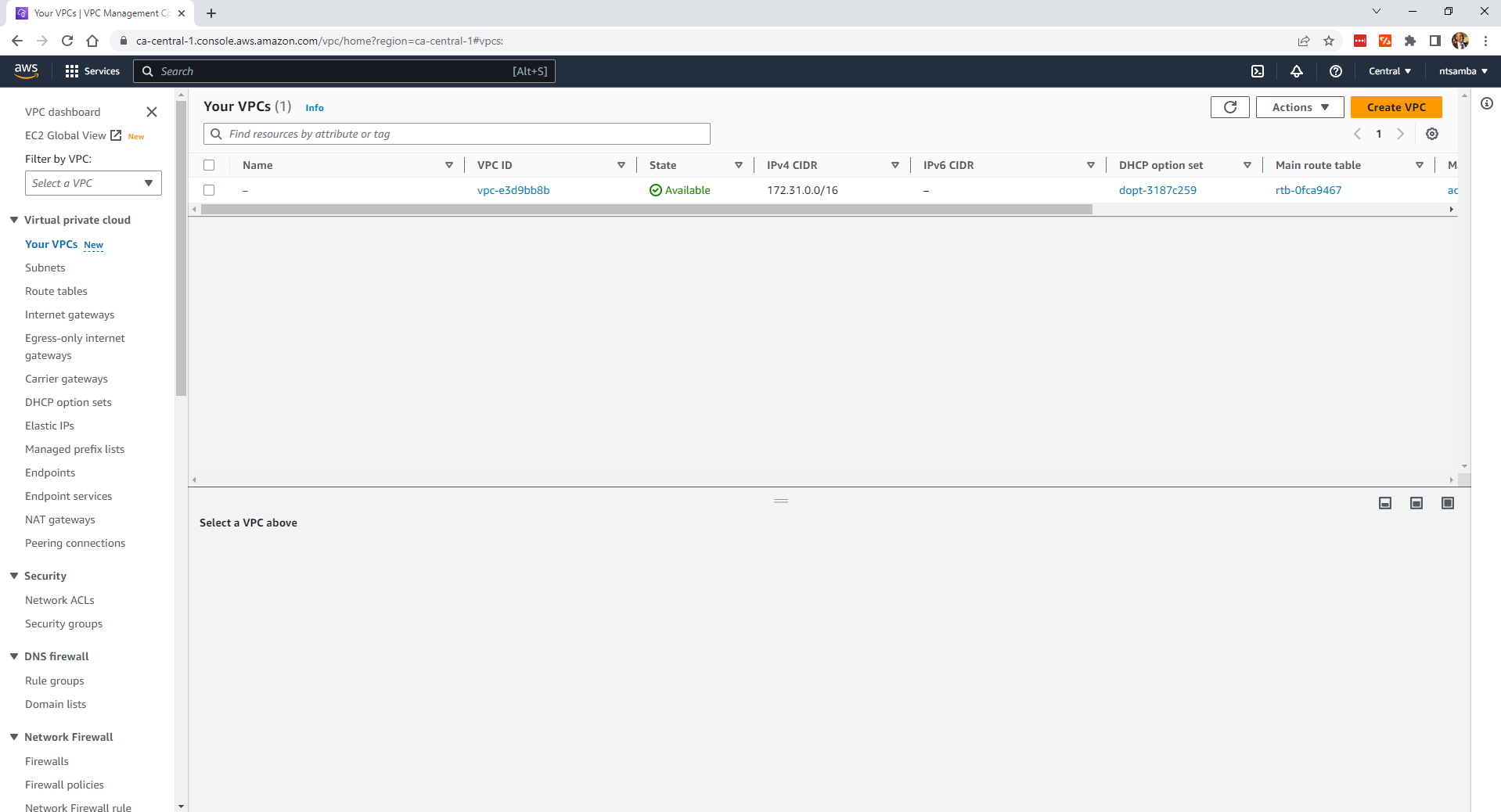
In addition, there’s currently only the default VPC:
Open your terminal, and in the terraform_dependencies directory, run the following command to initialize Terraform:
terraform initYour output looks like this:
Initializing the backend...
Initializing provider plugins...
- Finding latest version of hashicorp/aws...
- Installing hashicorp/aws v5.3.0...
...output omitted...Next, run the terraform plan command to review the changes that Terraform will make. Your output looks like this:
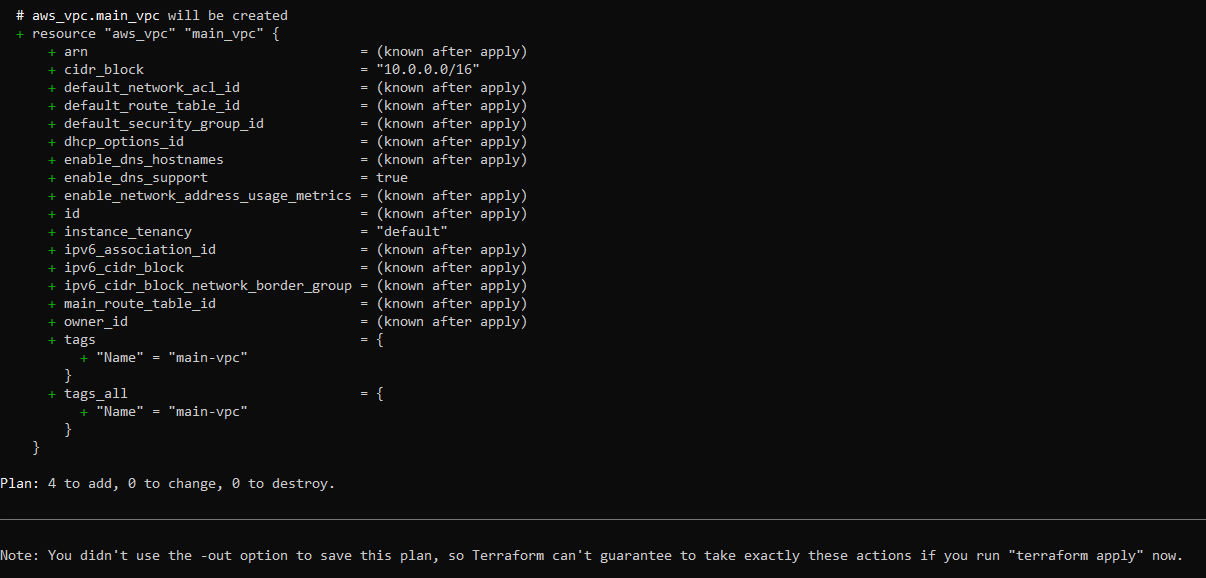
In the second to last statement (ie Plan: 4 to add, 0 to change, 0 to destroy), the code adds four resources: an EC2 Instance, a VPC, a subnet, and a security group.
To create these resources, run the terraform apply command. This command prompts you to confirm if you want to make changes.
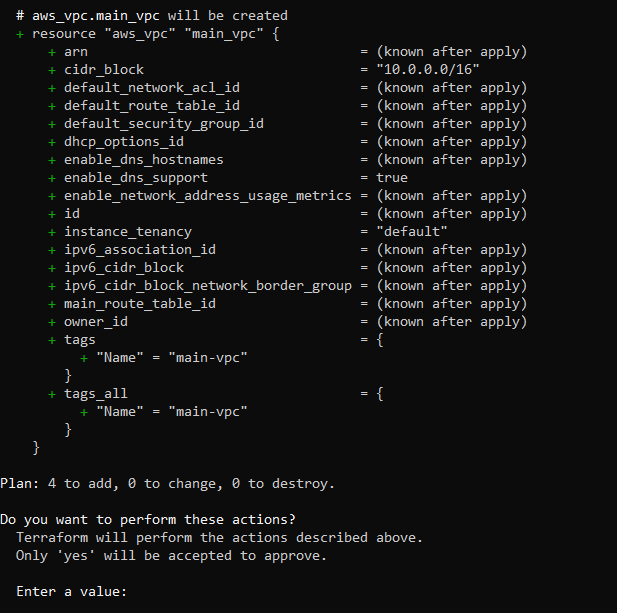
Enter yes. Your output looks like this:
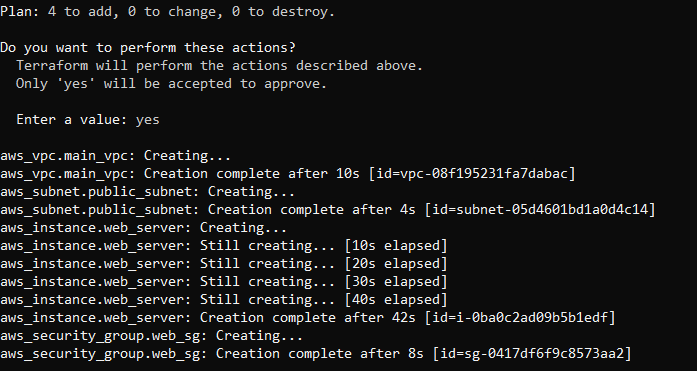
As you can see from the output, the VPC was created first, since it’s required by the subnet. Then the public_subnet was created because the web server requires it. The web_server instance depends on the public subnet and therefore it was created after the subnet. Lastly, the security group was created as it depends on both the web_server instance and the public subnet.
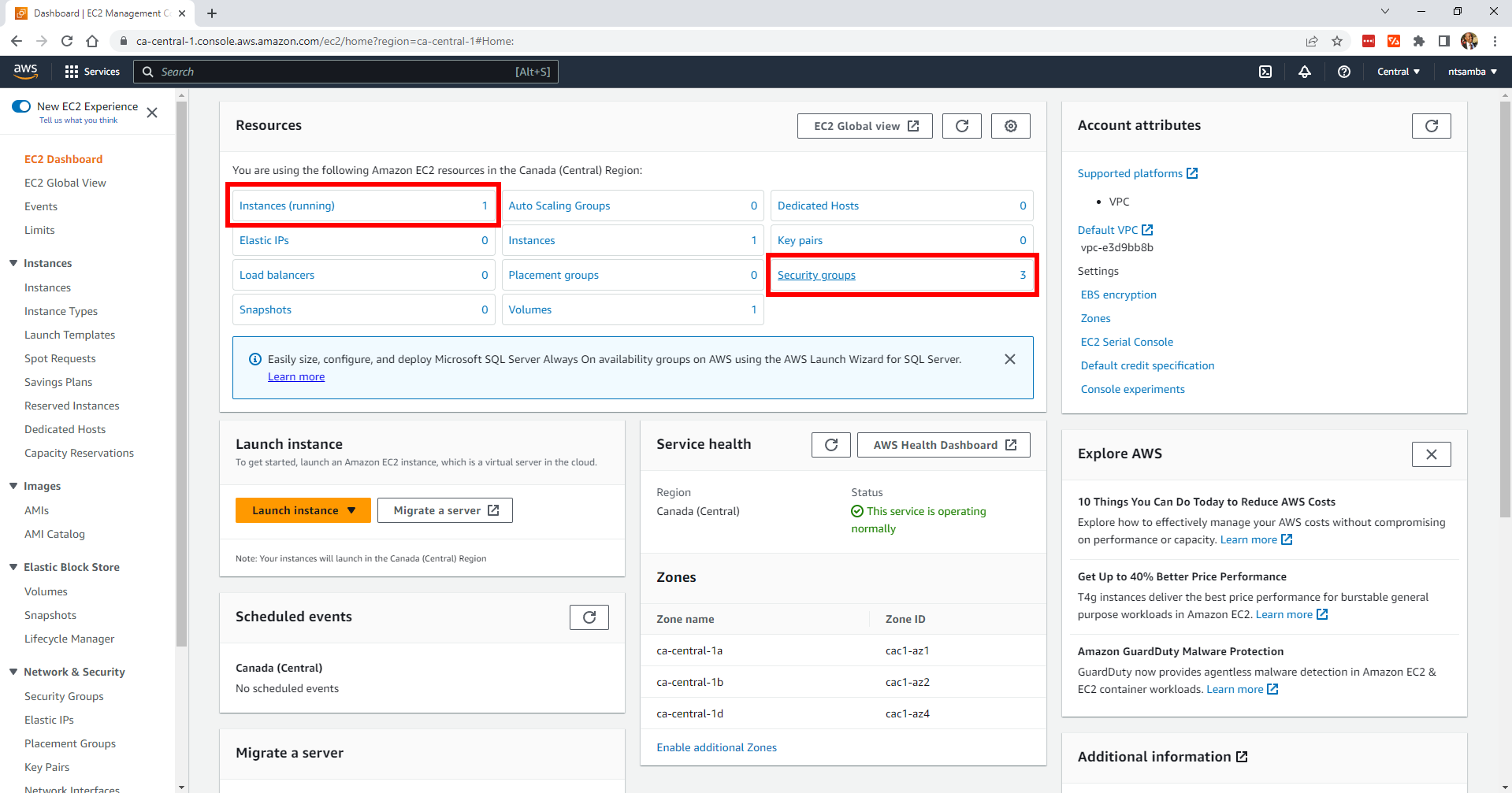
After running this command, you have a new EC2 instance as well as two new security groups:
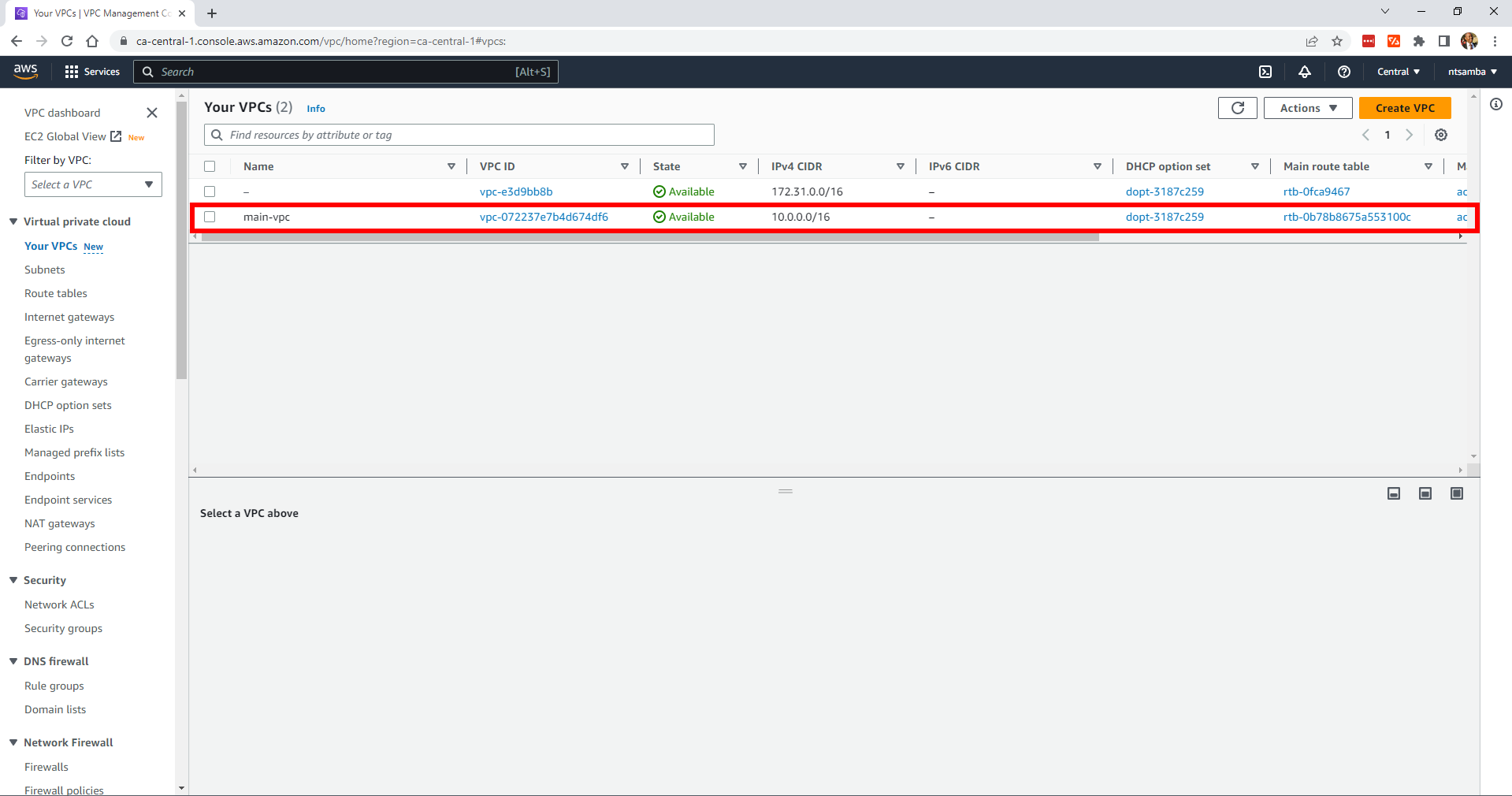
main-vpc has also been created:
And that’s how you create resources using explicit dependencies. Next, let’s explore the implicit dependencies.
Implicit Dependencies in Terraform
Implicit dependencies are dependencies that Terraform can infer automatically from the configuration of resources. For example, if a resource depends on the output of another resource, Terraform creates or updates the dependent resource after creating or updating the resource that produces the output. By leveraging these implicit dependencies, you can simplify your code and let Terraform handle the ordering of resource creation.
For instance, look at an example where you need to create web_server, vpc, public_subnet, and security_group, but you don’t want to explicitly specify the dependencies.
Start by replacing the contents of your main.tf file with the following:
provider "aws" {
region = "ca-central-1" # Replace with your desired AWS region
}
resource "aws_instance" "web_server_implicit" {
ami = "ami-0b18956f"
…
}
}
resource "aws_subnet" "public_subnet_implicit" {
vpc_id = aws_vpc.main_vpc.id
…
}
resource "aws_security_group" "web_sg_implicit" {
name = "web_sg"
description = "Web Security Group"
…
}
}
resource "aws_vpc" "main_vpc" {
cidr_block = "10.0.0.0/16"
… }
}As a reminder, the full code can be found in the
main_implicit.tffile of this GitHub repo.
Here, the EC2 instance called web_server implicitly depends on the subnet called public_subnet because the subnet ID is referenced in the subnet_id attribute of the instance. The public_subnet depends on the main-vpc-implicit VPC. Similarly, the security group web_sg implicitly depends on the instance and subnet because it references the instance in the ingress rule and the subnet indirectly through the instance.
Run the terraform destroy command to destroy all the resources you created with explicit dependencies.
Then run the terraform plan command. If you’re satisfied with the plan, run the terraform apply command to create the resources using implicit dependencies:
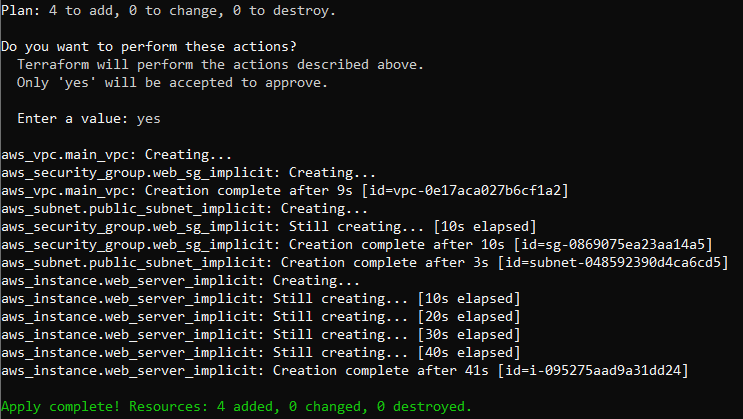
Now, if you check the EC2 instances, you should have an instance called Web Server Implicit:
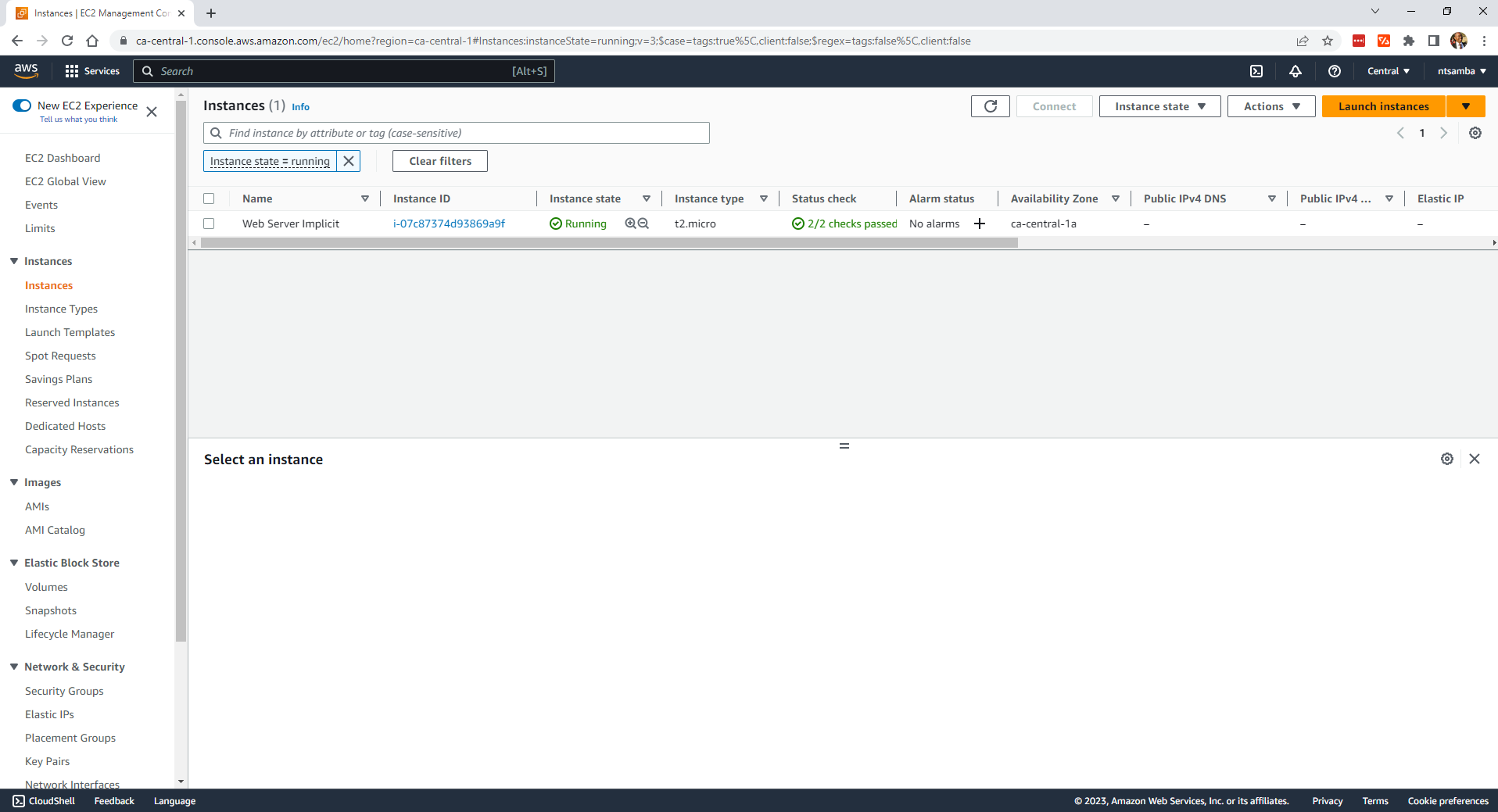
Additionally, if you check the VPCs, you’ll find a VPC named main-vpc-implicit:
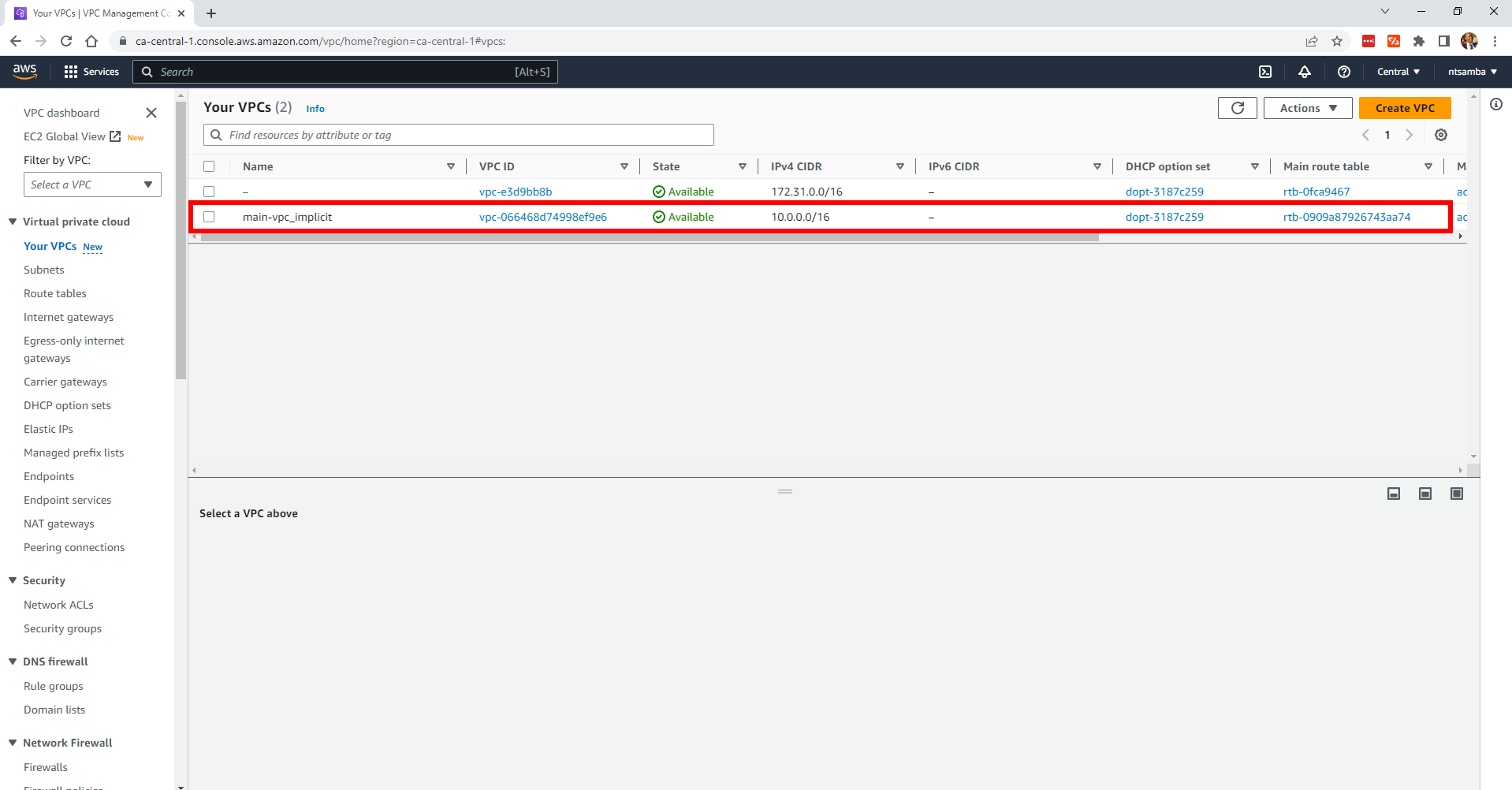
This example shows you that you can create the same infrastructure resources using either explicit or implicit dependencies.
Be sure to destroy the resources you created using the
terraform destroycommand so that you don’t incur charges.
Terraform Module Dependencies
A module in Terraform is a self-contained unit of configuration. Modules allow you to organize, reuse, and share infrastructure code, making it easier to manage complex infrastructure deployments.
Creating a Terraform module is easy. You just create a directory to represent the module, and then in the directory, you create a main.tf file. For example, to create a module named databases, simply create a directory called databases, and inside that, create a file called main.tf where you put in the HCL code to provision the databases.
Module dependencies allow you to create relationships between the modules and specify the order in which the modules should be instantiated and provisioned. This ensures that the modules are created in the correct sequence considering their dependencies on other modules.
To specify module dependencies, use the depends_on argument within a module block. The syntax for module dependency looks like this:
module "module_name" {
depends_on = [module.module_name, ...]
}For a deeper understanding, consider a scenario where you want to provision AWS resources using modular infrastructure with module dependencies. In this instance, you need to create a directory called modular_infrastructure that serves as the root directory. Then in the modular_infrastructure directory, create a directory called modules and a main.tf file.
In the main.tf file, add the following HCL code:
provider "aws" {
region = "ca-central-1"
}
module "network" {
source = "./modules/network"
}
module "compute" {
source = "./modules/compute"
subnet_id = module.network.public_subnet_id
depends_on = [module.network]
}Be sure to replace ca-central-1 with the region where you want to deploy the resources.
In this file, the aws provider is configured with the specified region, indicating that Terraform manages resources in the AWS provider located in the ca-central-1 region. Then the network module is declared using the module block. The source parameter specifies the relative path to the ./modules/network directory, where the module’s configuration is defined.
The compute module is declared using the module block. The source parameter specifies the relative path to the ./modules/compute directory, where the module’s configuration is defined. Additionally, the subnet_id variable is set to module.network.public_subnet_id, which refers to the output value public_subnet_id from the network module. You can also see the depends_on argument, which specifies that the compute module depends on the network module.
In the modules directory, create another directory named network, and inside it, create a main.tf file.
In the main.tf file, add the following HCL code:
resource "aws_vpc" "main_vpc" {
cidr_block = "10.0.0.0/16"
}
resource "aws_subnet" "public_subnet" {
vpc_id = aws_vpc.main_vpc.id
cidr_block = "10.0.1.0/24"
}
resource "aws_security_group" "web_sg" {
name = "web_sg"
description = "Web Security Group"
ingress {
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
}
output "public_subnet_id" {
value = aws_subnet.public_subnet.id
}In this file, the aws_vpc resource block is defined, representing an Amazon VPC configuration. The cidr_block parameter specifies the IPv4 address range for the VPC.
The aws_subnet resource block is also defined, representing a subnet within the VPC. The vpc_id parameter is set to aws_vpc.main_vpc.id, which refers to the id attribute of the aws_vpc resource declared previously. The cidr_block parameter specifies the IPv4 address range for the subnet.
The output block defines an output value named public_subnet_id. This output value captures the id attribute of the aws_subnet resource, making it available for other parts of the configuration. This output value can be referenced in other modules or accessed outside of Terraform for other purposes, including integration with external systems, manual reference, or reporting and auditing.
Because you’ve included these resource and output definitions, Terraform provisions the specified Amazon VPC and subnet resources based on the provided configurations. Initially, the aws_vpc resource is created, followed by the aws_subnet resource. The output value public_subnet_id captures the subnet’s ID for a potential reference by other modules or for external use.
Now, create another directory in the modules directory called compute. Inside this directory, create the main.tf file and add the following configuration code:
variable "subnet_id" {
description = "ID of the subnet where the instance will be launched"
}
resource "aws_instance" "web_server" {
ami = "ami-0b18956f"
instance_type = "t2.micro"
subnet_id = var.subnet_id
tags = {
Name = "Web Server"
}
}In this file, the variable block declares the subnet_id variable. Variables in Terraform allow you to parameterize your configurations and pass values between modules.
The aws_instance resource block is defined, representing an Amazon EC2 instance. The ami parameter specifies the ID of the Amazon Machine Image (AMI) to use for the instance. The instance_type parameter sets the instance type (ie t2.micro). The subnet_id parameter is set to the value of the subnet_id variable, which is expected to be provided when using this module, and it allows you to specify the subnet in which the EC2 instance should be launched.
The tags block is used to assign tags to the EC2 instance. In this example, the instance is given a tag with the key Name and the value Web Server.
By including these configurations, Terraform creates an EC2 instance using the specified AMI, instance type, and subnet ID.
Now, you’re done setting up the modules, and your directory structure should look like this:
modularInfrastructure/
├── main.tf
└── modules
├── compute
│ └── main.tf
└── network
└── main.tfWith this configuration, the compute module now explicitly depends on the network module using depends_on = [module.network]. This ensures that the network resources are created before the compute resources.
Please note: Using
depends_onto manage module dependencies is typically not recommended, as Terraform automatically determines the correct dependency order based on resource references. However, if you have specific requirements that necessitate explicit dependencies,depends_oncan be used as shown here.
Using depends_on to manage module dependencies is generally discouraged because Terraform’s strength lies in its ability to automatically infer dependency order based on resource references. Relying on depends_on can obscure the actual dependency relationships within your code, making it harder to understand and maintain. Additionally, it can lead to unexpected outcomes, such as creating unnecessary delays in resource provisioning or updates, as Terraform might wait for dependencies that would have been handled more efficiently by its automatic dependency resolution. This approach also hampers parallelism and can result in longer execution times.
Moreover, using depends_on can create a potential maintenance burden, as changes to the codebase or infrastructure may require manual adjustments to these explicit dependencies. This can introduce fragility and increase the chances of errors if not meticulously managed.
In contrast, allowing Terraform to determine dependencies through resource references promotes a cleaner and more declarative code structure. This helps in visualizing and understanding the relationship between resources, simplifying troubleshooting and updates. Overall, leveraging Terraform’s built-in dependency handling ensures better code maintainability, scalability, and adherence to best practices.
Run the command terraform init in the modular_infrastructure directory to initialize Terraform. Then run terraform plan. If you’re happy with the plan, run terraform apply to apply the changes and provision your infrastructure.
Best Practices for Terraform Configurations

Following are some best practices that you should consider when working with Terraform configurations:
Promote a Modular and Maintainable Infrastructure Codebase
When expressing dependencies between modules in Terraform, it’s advisable to adhere to best practices that promote a modular, efficient, and maintainable infrastructure codebase. This means you should embrace Terraform’s inherent dependency resolution mechanism by relying on resource references to dictate the order of provisioning and updates. Avoid using depends_on unless it’s absolutely necessary, such as when dealing with external resources or enforcing specific creation sequences.
Additionally, structure your modules with a focus on reusability and composability. Design smaller, specialized modules that encapsulate distinct components of your infrastructure, and then combine them to create higher-level constructs. Utilize input and output variables to communicate data between parent and child modules, keeping them decoupled and facilitating effective information sharing.
Moreover, document dependencies within your modules, providing clarity for both present and future collaborators. By adhering to these practices, you’ll build a robust and adaptable Terraform codebase that harnesses the tool’s full potential in managing module dependencies while maintaining readability and scalability.
Decide between Implicit and Explicit Dependencies
Deciding between implicit and explicit dependencies is important because it allows you to control the order that resources are created. This not only ensures that dependencies are satisfied but also avoids potential issues or errors during provisioning.
The general rule is to use implicit dependencies whenever you can. Terraform’s implicit dependency mechanism is great for straightforward situations because it automatically figures out dependencies based on resource references. However, when things get more complex, explicit dependencies may be necessary. In general, Terraform dependencies simplify the configuration and allows Terraform to handle the ordering of resource creation automatically.
In comparison, you should use explicit dependencies using depends_on sparingly. Explicit dependencies can introduce complexity and make the configuration harder to understand and maintain. You can use explicit dependencies in rare cases where implicit dependencies cannot be determined correctly by Terraform or when specific resource ordering is crucial.
Manage Complex Dependencies
When working with complex configurations, you need to document the dependencies between resources and modules to help other team members understand the intended ordering and relationships.
You should also utilize module separation, breaking down complex configurations into smaller, focused modules. This can help manage dependencies and make the overall configuration more modular and maintainable. Each module should have a well-defined purpose and clear inputs and outputs.
Keep Configurations Maintainable
In order to maintain your configurations, you need to leverage input variables and modules to make configurations more flexible, reusable, and easier to maintain. Use variables for configurable values and abstract common infrastructure patterns into modules for reuse across multiple projects.
Additionally, organize your Terraform code into logical modules and keep the module directory structure clean and consistent. This helps in locating and managing resources easily. You can also use version control systems (such as Git) to track changes, collaborate with teammates, and maintain a history of your infrastructure code. This enables you to roll back changes when needed.
You should also assign meaningful names to resources and use appropriate tags to improve the readability and maintainability of the configurations.
For instance, you can tag the aws instance like this:
tags = {
Name = "Web Server"
Environment = "Production"
Project = "My Project"
}
These tags provide additional context and metadata about the resource, making it easier to identify and manage resources in the future. It then becomes easier to understand the purpose and role of each resource, especially when dealing with larger infrastructures and multiple resources of the same type.
Finally, regularly review and refactor your Terraform configurations to remove duplication, simplify code, and improve overall maintainability. This helps in keeping the configurations clean and manageable over time.
Troubleshooting and Edge Cases

To handle errors and edge cases in Terraform, you can employ the following strategies:
Error Handling
If there are dependency cycles or conflicts in resource dependencies, Terraform will raise errors during plan and apply. You should review error messages, identify the root cause, and rectify the configuration accordingly.
In the examples discussed here, Terraform would report errors if there were any conflicts or issues with the resource dependencies. You can leverage input validation, such as using conditional expressions or variable validation, to handle potential errors related to resource dependencies.
Retry Mechanisms
For transient errors (i.e. errors that resolve themselves) during resource provisioning, Terraform automatically retries the provisioning process. For instance, if there’s a network connectivity issue or if a service is temporarily unavailable, Terraform will retry creating the resource until it succeeds or reaches the maximum retry limit. This built-in retry mechanism helps handle transient errors automatically.
By carefully designing your resource dependencies, understanding error messages, reviewing Terraform’s documentation on error handling, and taking advantage of Terraform’s built-in retry mechanisms, you can effectively manage errors and handle edge cases during infrastructure provisioning.
Dependency Issues
To identify dependency issues in Terraform, run the terraform plan command. If there are any unresolved dependencies or even circular dependencies between resources, Terraform will report them as errors or warnings during the planning phase. This means that you should pay close attention to any error messages or warnings provided by Terraform, as they often indicate missing or conflicting dependencies.
Additionally, always review the resource references within your configuration to ensure all resources are properly referenced and that any dependencies between them are correctly defined. You can also use the terraform graph command to generate a graph of the dependencies between your resources. This can be useful in identifying dependency issues.
Circular Dependencies
The obvious way to resolve circular dependencies is to break them. One approach is to refactor your configuration to break the circular dependency by introducing an intermediary resource or module. By doing so, you can create the necessary resources in a specific order without direct circular references.
Alternatively, you can split resources into separate configurations and manage their dependencies separately, therefore avoiding circular references.
Lastly, you can utilize the depends_on argument to explicitly define the dependency order between resources. However, be cautious and only use it as a last resort, as it can introduce complexity and make your configuration less maintainable.
Whenever possible, circular dependencies should be avoided, as they can introduce challenges and make your Terraform configuration harder to manage. You should design your infrastructure and dependencies in a way that follows best practices to prevent circular dependencies from occurring in the first place.
Conclusion
In this article, you learned all about dependencies in Terraform and how to effectively manage them. You also learned about depends_on in Terraform and that it’s a configuration attribute that allows you to explicitly define dependencies between resources.
If you want to learn more about this topic, check out the official depends_on documentation or this discussion from the HashiCorp blog about how to avoid and resolve circular dependencies.
Looking to simplify your build automation further? Give Earthly a try. It could be the perfect complement to your chosen IaC tool.
Turn your engineering standards into automated guardrails that provide feedback directly in pull requests, with 100+ guardrails included out of the box and support for the tools and CI/CD systems you already have.


